PyFlink 流批一体以及 BTC.com 在区块链领域的专业实践
概要:
大家好,我们是 BTC.com 团队。 2020 年,我们有幸接触到了 Flink 和 PyFlink 生态,从团队自身需求出发,完善了团队内实时计算的任务和需求,搭建了流批一体的计算环境。
在实现实时计算的过程中,我们在实践中收获了一些经验,在此分享一些这方面的心路历程。
0x01 TOC
- 困惑 • 描述 • 思考 • 行动
- 流批一体的架构
- 架构
- 效果
- zeppelin,PyFlink on k8s 等实践
- zeppelin
- PyFlink on k8s
- 区块链领域实践
- 展望 • 总结
0x02 困惑 • 描述 • 思考 • 行动
作为工程师,我们每天都在不断地了解需求,研发业务。
有一天,我们被拉到了一次团队总结会议上,收到了以下的需求:
销售总监 A:
我们想要知道销售的�历史和实时转化率、销售额,能不能统计一下实时的 TOP5 的商品,还有就是大促时候,用户实时访问、商品实时浏览量 TOP5 的情况呢,可以根据他历史访问的记录实时推荐相关的吗。
市场总监 B:
我们想要知道市场推广的效果,每次活动的实时数据,不然我们的市场投放无法准确评估效果,及时反馈啊。
研发总监 C:
有些用户的 bug 无法复现,日志可以再实时一点吗?传统日志分析,需要一定的梳理,可不可以直接清洗 / 处理相关的数据?
采购总监 D:
这些年是不是流行数字化,采购这边想预测采购需求,做一下实时分类和管理支出,预测未来供应来源,完善一下成本。这个有办法做吗?还有有些供应商不太稳定啊,能监控到他们的情况吗?
运维总监 E:
网站有时候访问比较慢,没有地方可以看到实时的机器情况,搞个什么监控大屏,这个有办法解决吗?
部门领导 F:
可以实现上面的人的需求吗。
做以上的了解之后,才发现,大家对于数据需求的渴望程度,使用方不仅需要历史的数据,而且还需要实时性的数据。
在电商、金融、制造等行业,数据有着迅猛的增长,诸多的企业面临着的新的挑战,数据分析的实时处理框架,比如说做一些实时数据分析报表、实时数据处理计算等。
和大多数企业类似,在此之前,我们是没有实时计算这方面的经验和积累的。这时,就开始困惑了,怎样可以更好地做上面的需求,在成本和效果之间取得平衡,如何设计相关的架构。

穷则思变,在有了困惑以后,我们就开始准备梳理已有的条件和我们到底需要什么。
首先我们的业务范围主要在区块链浏览器与数据服务、区块链矿池、多币种钱包等。在区块链浏览器的业务里,BTC.com 目前已是全球领先的区块链数据服务平台,矿池业务在业内排行第一,区块链浏览器也是全球前三大浏览器之一。
首先,我们通过 parser 解析区块链上的数据,得到各方面的数据信息,可以分析出每个币种的地址活跃度、地址交易情况、交易流向、参与程度等内容。目前,BTC.com 区块链浏览器与行业内各大矿池和交易所等公司都有相关合作,可以更好地实现一些数据的统计、整理、归纳、输出等。
面向的用户,不仅有专业的区块链开发人员,也有各样的 b 端和 c 端用户,c 端用户可以进行区块链地址的标注,智能合约的运行,查看智能合约相关内容等,以及链上数据的检索和查看。b 端用户则有更专业的支持和指导,提供 API、区块链节点等一些的定制以及交易加速、链上的业务合作、数据定制等。
从数据量级来讲,截至目前,比特币大概有 5 亿笔交易,3000 多万地址,22 亿输出(output:每笔交易的输出),并且还在不断增长中。以太坊的话,则更多。而 BTC.com 的矿池和区块链浏览器都支持多币种,各币种的总数据量级约为几十 T。
矿池是矿工购买矿机设备后连接到的服务平台,矿工可以通过连接矿池从而获取更稳定的收益。这是一个需要保证 7 * 24 小时稳定的服务,里面有矿机不断地提交其计算好的矿池下发的任务的解,矿池将达到网络难度的解进行广播。这个过程也可以认为是近乎是实时的,矿机通过提交到服务器,服务器内部再提交到 kafka 消息队列,同时有一些组件监听这些消息进行消费。而这些提交上来的解可以从中分析出矿机的工作状态、算力、连接情况等。
在业务上,我们需�要进行历史数据和实时数据的计算。
历史数据要关联一些币价,历史交易信息,而这些交易信息需要一直保存,是一种典型的批处理任务。
每当有新区块的确认,就有一些数据可以得到处理和分析,比如某个地址在这个区块里发生了一笔交易,那么可以从其交易流向去分析是什么样的交易,挖掘交易相关性。或者是在这个区块里有一些特殊的交易,比如 segwit 的交易、比如闪电网络的交易,就是有一些这个币种特有的东西可以进行解析分析和统计。并且在新区块确认时的难度预测也有所变化。
还有就是大额交易的监控,通过新区块的确认和未确认交易,锁定一些大额交易,结合地址的一些标注,锁定交易流向,更好地进行数据分析。
还有是一些区块链方面的 OLAP 方面的需求。

总结了在数据统计方面的需求和问题以后,我们就开始进行思考:什么是最合适的架构,如何让人员参与少,成本低。
解决问题,无非就是提出假设,通过度量,然后刷新认知。
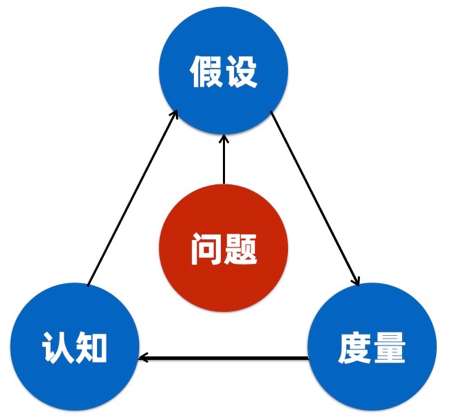
在浏览了一些资料以后,我们认为,大部分的计算框架都是通过输入,进行处理,然后得到输出。首先,我们要获取到数据,这里数据可以从 MySQL 也可以从 Kafka,然后进行计算,这里计算可以是聚合,也可以是 TOP 5 类型的,在实时的话,可能还会有窗口类型的。在计算完之后,将结果做下发,下发到消息渠道和存储,发送到微信或者钉钉,落地到 MySQL 等。
团队一开始尝试了 spark,搭建了 yarn,使用了 airflow 作为调度框架,通过做 MySQL 的集成导�入,开发了一些批处理任务,有着离线任务的特点,数据固定,量大,计算周期长,需要做一些复杂操作。
在一些批处理任务上,这种架构是稳定的,但是随着业务的发展,有了越来越多的实时的需求,并且实时的数据并不能保证按顺序到达,按时间戳排序,消息的时间字段是允许前后有差距的。在数据模型上,需求驱动式的开发,成本相对来说,spark 的方式对于当时来说较高,对于状态的处理不是很好,导致影响一部分的效率。
其实在 2019 年的时候,就有在调研一些实时计算的事情,关注到了 Flink 框架,当时还是以 java 为主,整体框架概念上和 spark 不同,认为批处理是一种特殊的流,但是因为团队没有 java 方面的基因和沉淀,使用 Flink 作为实时计算的架构,在当时就暂告一个段落。在 2020 年初的时候,不管是阿里云还是 infoq,还是 b 站,都有在推广 PyFlink,而且当时尤其是程鹤群和孙金城的视频以及孙金城老师的博客的印象深刻。于是就想尝试 PyFlink,其有着流批一体的优势,而且还支持 Python 的一些函数,支持 pandas,甚至以后还可以支持 tensorflow、keras,这对我们的吸引力是巨大的。在之后,就在构思我们的在 PyFlink 上的流批一体的架构。
0x03 流批一体的架构
架构
首先我们要梳理数据,要清楚数据从哪里来。在以 spark 为主的时期,数据是定期从数据源加载(增量)数据,通过一定的转换逻辑,然后写入目的地,由于数据量和业务需要,延迟通常在小时级别,而实时的话,需要尽可能短的延迟,因此将数据源进行了分类,整体分成了几部分,一部分是传统的数据我们存放在 MySQL 持久化做保存,这部分之后可以直接作为批处理的计算,也可以导入 hive,做进一步的计算。实时的部分,实际上是有很多思路,一种方式是通过 MySQL 的 binlog 做解析,还有就是 MySQL 的 cdc 功能,在多方考量下,最后我们选择了 Kafka,不仅是因为其是优秀的分布式流式平台,而且团队也有对其的技术沉淀。
并且实际上在本地开发的时候,安装 Kafka 也比较方便,只需要 brew install kafka,而且通过 conduktor 客户端,也可以方便的看到每个 Topic 的情况。于是就对现有的 Parser 进行改造,使其支持 Kafka,在当收到新的区块时,会立即向 Kafka 发送一个消息,然后进行处理。
大概是在 2018 年的时候,团队将整体的业务迁移到了 kubernetes 上,在业务不断发展的过程中,其对开发和运维上来说,减轻了很多负担,所以建议有一定规模的业务,最好是迁移到 kubernetes,其对成本的优化,DevOps,以及高可用的支持,都是其他平台和传统方式无法比拟的。
在开发作业的过程中,我们在尽可能的使用 Flink SQL,同时结合一些 Java 、Python 的 UDF,UDAF,UDTF。每个作业通过初始化类似于以下的语句,形成一定的模式:
self.source_ddl = '''
CREATE TABLE SourceTable (xxx int) WITH
'''
self.sink_ddl = '''
CREATE TABLE SinkTable (xxx int) WITH
'''
self.transform_ddl = '''
INSERT INTO SinkTable
SELECT udf(xxx)
FROM SourceTable
GROUP BY FROM_UNIXTIME(`timestamp`, 'yyyyMMdd')
'''
在未来的话,会针对性地将数据进行分层,按照业界通用的 ODS、DWD、DWS、ADS,分出原始层,明细层和汇总层,进一步做好数据的治理。
效果
最终我们团队基于 PyFlink 开发快速地完成了已有的任务,部分是批处理作业,处理过去几天的数据,部分是实时作业,根据 Kafka 的消息进行消费,目前还算比较稳定。
部署时选择了kubernetes,具体下面会进行分享。在 k8s 部署了 jobmanager 和 taskmanager,并且使用 kubernetes 的 job 功能作为批处理作业的部署,之后考虑接入一些监控平台,比如 Prometheus 之类的。
在成本方面,由于是使用的 kubernetes 集群,因此在机器上只有扩展主机的成本,在这种方式上,成本要比传统的 yarn 部署方式要低,并且之后 kuberntes 会支持原生部署,在扩展 jobmanager 和 taskmanager 上面会更加方便。
0x04 Zeppelin,PyFlink on k8s 等实践
Zeppelin 是我们用来进行数据探索和逻辑验证,有些数据在本地不是真实数据,利用 Zeppelin 连接实际的链上数据,进行计算的逻辑验证,当验证完成后,便可转换成生产需要的代码进行部署。
一、kubernetes 上搭建 PyFlink 和 Zeppelin
- 整理后的部署 Demo 在 github,可以参阅这里
- 关于配置文件修改
1). flink-conf.yaml
taskmanager.numberOfTaskSlots: 10
这里可以调整 Taskmanager 可运行的的 job 的数量
2). zeppelin-site.xml
cp conf/zeppelin-site.xml.template conf/zeppelin-site.xml; \
sed -i 's#<value>127.0.0.1</value>#<value>0.0.0.0</value>#g' conf/zeppelin-site.xml; \
sed -i 's#<value>auto</value>#<value>local</value>#g' conf/zeppelin-site.xml
- 修改请求来源为 0.0.0.0,如果是线上环境,建议开启白名单,加上 auth 认证。
- 修改 interpreter 的启动模式为 local,auto 会导致在集群启动时,以 k8s 的模式启动,目前 k8s 模式只支持 Spark, local 模式可以理解为,Zeppelin 将在本地启动一个连接 Flink 的 interpreter 进程。
- Zeppelin 和在本地提交 Flink 作业类似,也需要 PyFlink 的基础环境,所以需要将 Flink 对应版本的 jar 包放入镜像内。
- Zeppelin 访问代理
nginx.ingress.kubernetes.io/configuration-snippet: |
proxy_set_header Upgrade "websocket";
proxy_set_header Connection "Upgrade";
Zeppelin 在浏览器需要和 server 端建立 socket 连接,需要在 ingress 添加 websocket 配置。
- Flink 和 Zeppelin 数据持久化
- mountPath: /opt/flink/lib
- mountPath: /zeppelin/notebook/
- 对 Flink 的 lib 做持久化的目的是需要 jar 包时可以直接进入 pod 下载,而无需更换镜像。
- Zeppelin 的任务代码会存放在 notebook 目录下,保存编写好的代码。
- PyFlink 本地提交 job
1). 本地安装 PyFlink
$ pip3 install apache-flink==1.11.1
2). 测试 demo
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(
env,
environment_settings=EnvironmentSettings.new_instance().use_blink_planner().build()
)
sink_ddl = """
create table Results (word VARCHAR, `count` BIGINT) with ( 'connector' = 'print')
"""
t_env.sql_update(sink_ddl)
elements = [(word, 1) for word in content.split(" ")]
# 这里也可以通过 Flink SQL
t_env.from_elements(elements, ["word", "count"]) \
.group_by("word") \
.select("word, count(1) as count") \
.insert_into("Results")
t_env.execute("word_count")
if __name__ == '__main__':
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")
word_count()
或者是实时处理的 Demo:
def handle_kafka_message():
s_env = StreamExecutionEnvironment.get_execution_environment()
# s_env.set_stream_time_characteristic(TimeCharacteristic.EventTime)
s_env.set_parallelism(1)
st_env = StreamTableEnvironment \
.create(s_env, environment_settings=EnvironmentSettings
.new_instance()
.in_streaming_mode()
.use_blink_planner().build())
source_ddl = '''
CREATE TABLE SourceTable (
word string
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'Topic',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'connector.properties.zookeeper.connect' = 'localhost:2121',
'format.type' = 'json',
'format.derive-schema' = 'true'
)
'''
sink_ddl = """
create table Results (word VARCHAR) with ('connector' = 'print')
"""
st_env.sql_update(sink_ddl)
st_env.sql_update(source_ddl)
st_env.from_path("source").insert_into("sink")
st_env.execute("KafkaTest")
if __name__ == '__main__':
handle_kafka_message()
- 本地测试 Flink 提交 job
$ flink run -m localhost:8081 -py word_count.py
python/table/batch/word_count.py
Job has been submitted with JobID 0a31b61c2f974bcc3f344f57829fc5d5
Program execution finished
Job with JobID 0a31b61c2f974bcc3f344f57829fc5d5 has finished.
Job Runtime: 741 ms
- PyFlink 本地提交 Python Job,这里将相关代码进行了打包。
$ zip -r flinkdemo.zip ./*
$ flink run -m localhost:8081 -pyfs flinkdemo.zip -pym main
- Kubernetes 通过集群本身的 Job 功能来提交 Job,之后会做自研一些 UI 后台界面做作业管理与监控。
0x05 在区块链领域实践
随着区块链技术的越来越成熟,应用越来越多,行业标准化、规范化的趋势也开始显现,也越来越依赖于云计算、大数据,毕竟是数字经济的产物。BTC.com 也在扎根于区块链技术基础设施,为各类公司各类应用提供数据和业务上的支持。
近些年,有个词火遍了 IT 业界,中台,不管是大公司还是创业公司,都喜欢扯上这个概念,号称自己业务中台,数据中台等。我们的理解中,中台是一种整合各方面资源的能力,从传统的单兵作战,到提升武器装备后勤保障,提升作战能力。在数据上打破数据孤岛,在需求快速变化的前台和日趋稳定的后台中取得平衡。而中台更重要的是服务,最终还是要回馈到客户,回馈到合作伙伴。
在区块链领域,BTC.com 有着深厚的行业技术积累,可以提供各方面数据化的能力。比如在利用机器学习进行链上数据的预估,预估 eth 的 gas price,还有最佳手续费等,利用 keras 深度学习的能力,进行一些回归计算,在之后也会将 Flink、机器学习和区块链结合起来,对外提供更多预测类和规范化分类的数据样本,之前是在用定时任务不断训练模型,与 Flink 结合之后,会更加实时。在这方面,以后也会提供更多的课题,比如币价与 Defi,舆情,市场等的关系,区块链地址与交易的标注和分类。甚至于将机器学习训练的模型,放于 IPFS 网络中,通过去中心化的代��币进行训练,提供方便调用样本和模型的能力。
在目前,BTC.com 推出了一些通过数据挖掘实现的能力,包括交易推送、OLAP 链上分析报表等,改善和提升相关行业和开发者实际的体验。我们在各种链上都有监控节点,监控各区块链网络的可用性、去中心化程度,监控智能合约。在接入一些联盟链、隐私加密货币,可以为联盟链、隐私加密货币提供这方面的数据能力。BTC.com 将为区块链产业生态发展做出更多努力,以科技公司的本质,以技术发展为第一驱动力,以市场和客户为导向,开发创新和融合应用,做好基础设施。
0x06 展望 / 总结
从实时计算的趋势,到流批一体的架构,通过对 PyFlink 和 Flink 的学习,稳定在线上运行了多种作业任务,对接了实际业务需求。并且搭建了 Zeppelin 平台,使得业务开发上更加方便。在计算上尽可能地依赖 SQL,方便各方面的集成与调试。
在社区方面,PyFlink 也是没有令我们失望的,较快的响应能力,不断完善的文档。在 Confluence 上也可以看到一些 Flink Improvement Proposals,其中也有一些是 PyFlink 相关的,在不远的将来,还会支持 Pandas UDAF,DataStream API,ML API,也期望在之后可以支持 Joblistener,总之,在这里也非常感谢相关团队。
未来的展望,总结起来就是,通过业务实现数据的价值化。而数据中台的终局,是将数据变现。